2022. 9. 27. 17:03ㆍ대학원 입시/Paper Review
개요
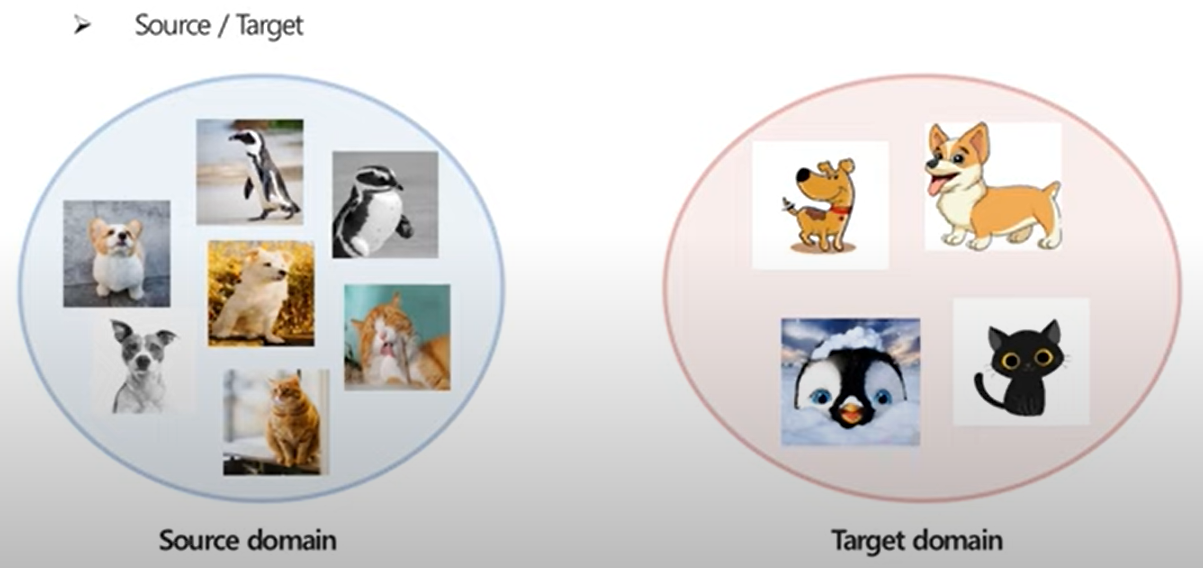
Image Classification Task를 예로 들때, train 과정에서 사용되는 dataset과 operation 에서 사용되는 dataset의 domaim의 분포가 달라지면서 domain shift 가 발생한다 (DSLR 이미지로 학습후, 만화 그림으로 예측) 이 경우 성능이 저하될수 있다
여러 도메인의 dataset을 수집하여 학습하기는 실제로 어렵기에 이를 해결하는 방법론이 등장하게 되었다
기존의 general 한 모델에서 특정 domain에 맞추어 transfer learning이 한가지 방법이 될수 있다
주요 분류
1. Source-domain, Target-domain
2. Transfer Leaning의 분류
| task 같음 | task 다름 | |
| domain 같음 | Usual Learning | Inductive Transfer Learning |
| domain 다름 | Transductive Transfer Learning | Unsupervised Transfer Learning |
진한 글씨가 Transfer Learning이며, 그 중에서 Transductive Transfer Learning을 Domain Adaption(DA)이라 한다
3. Target source의 labeled data의 비율로 분류
| Labeling O | Labeling small | Labeling X | Target source data X |
| Supervised domain adatption (SDA) |
Semi-supervised domain adatption |
Unsupervised domain adatption (UDA) |
Domain generalization |
DomainNet의 Dataset
DomainNet: http://ai.bu.edu/M3SDA/ skecth, real, painting, infograph ...
Domain Adaption 방법론
1. DANN (Domain-Adversarial Training of Neural Networks - UDA 방법론)
Data Labeling
 |
 |
| target domain에는 class labeling X | source와 target의 domain labeling O |
Loss
Target risk <= Source risk + Domain divergence
Source risk : class 분류 성능을 의미하며, 정확한 분류를 위해서 loss를 낮추어야 함
Domain divergence : domain을 구분하는 성능으로, 구분을 잘 못하도록 loss가 낮아야한다 (domain에 관계없이 동일한 class로 인식하도록 만드는것이 목표)
Adversarial predictor(Label, Domain predictor) 를 이용해서 Loss 설계
gradient reverse layer를 추가하여 Ld(domain loss)를 gradient에서 빼주어 domain 구분을 잘 못하도록 만든다
class는 올바르게 분류하고, domain은 구분하지 못하도록 loss를 설계함


2. CCSA-loss (Unified Deep Supervised Domain Adaptation and Generalization - SDA 방법론)
동일한 데이터 양에서는 Supervised learning이 Unsupervised learning보다 성능이 좋으며, Unsupervised learning의 경우 좀 더 많은 데이터를 필요로 한다. CCSA-loss는 Supervised learning을 사용한다 (target domian에서 labeled data가 소수)
Loss
CCSA-loss : Classifiation Loss and Constrastive Semantic Alignment Loss
Target risk <= Source risk + Domain divergence 일때,
Source risk : class 분류 성능을 의미하며, 정확한 분류 성능으로 loss를 낮추어야 함
Domain divergence : domain을 구분하는 성능으로, 구분을 잘 못하도록 loss가 낮아야한다 (domain에 관계없이 동일한 class로 인식하도록 만드는것이 목표)
전체 Loss : Lccsa = Lc + Lsa + Ls 로 설정하여, domain divergence를 세분화함
Lc(source risk) : Classifiation Loss : labeled source 데이터에 대한 class 분류 성능 향상
Lsa(domain divergence) : Semantic alignment loss : class가 같을때 domain을 구분하지 못하도록 feature vector 거리를 가깝게 만든다
Ls(domain divergence) : Separation loss : class가 다른 경우 feature vector 거리가 멀게 만들며, margin term을 추가하여 class 간 최소한의 거리를 만들도록 한다
ce = ce_loss(src_pred, src_label)
csa = csa_loss(src_feature, target_feature,(src_label == target_label).float())
loss = (1 - alpha) * ce + alpha * csahttps://github.com/YooJiHyeong/CCSA_PyTorch
Data Augmentation
데이터양이 부족하여, source, target domain간의 pair를 만들어 학습함

3. SagNet(Reducing Domain Gap by Reducing Style Bias)
https://arxiv.org/pdf/1910.11645.pdf
CNN의 feature extraction 과정은 사람이 물체의 shape으로 물체를 식별하는 방법과 달리 style에 집중하게 된다. 이런 bias때문에 domain shift가 발생하면 성능이 하락하게 된다. 따라서 bias를 줄이는 방법으로 학습을 진행한다

Network
Feature Extractor : content와 style feature vector 추출
Content-Biased Network : feature vector를 style randomization후, content를 이용하여 예측하도록 설계
Style-Biased Network : feature vector를 content randomization후, style을 이용하여 예측하도록 설계
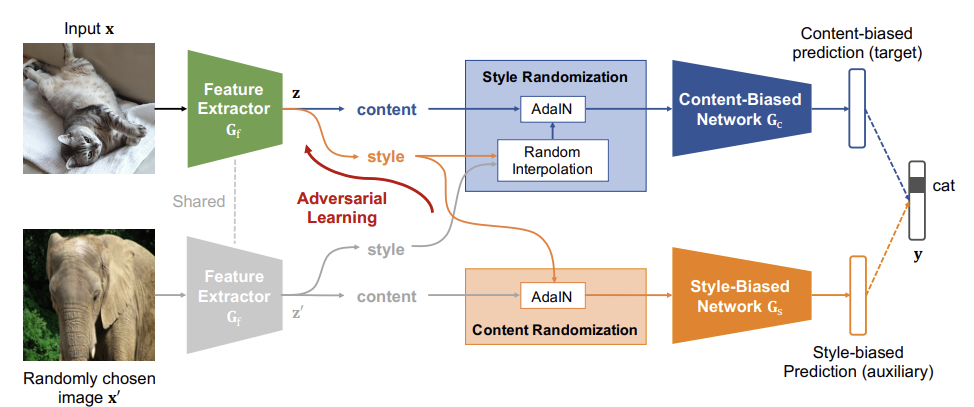
Train, Predict시 사용하는 Network
Train : 1. Contetn-Biased Learning : Feature Extractor -> Content-biased network
2. Adversarial Style-Biased Learning : Feature Extractor -> Style-biased network
Predict : Content-Biased Learning만 사용
Learning
1. Content-Biased Learning

input(x)과 random image(x')를 feature generate Gf를 통과한후, feature(z와 z')에 SR을 적용하고 content-biased loss를 구한다. Gf, Gc의 weight 업데이트, x, x'의 style을 AdaIN 적용
2. Adversial Style-Biased Learning
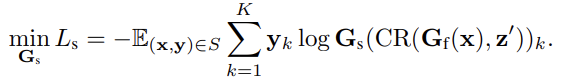
input과 random image를 feature generate Gf를 통과한후, feature에 CR을 적용하여 style-biased loss를 구한다
Gs의 weight 업데이트, x'의 content, x의 style을 AdaIN 적용
Style Representation
Feature Extractor를 통과한 feature로 부터 모든 채널에 대해서 mean과 std를 구한다
mean과 std로 이미지의 style을 표현하게 된다

AdaIN(Adaptive Instance Normalization)
https://lifeignite.tistory.com/48

이미지 x의 style (mean, std)를 뺀후, y의 style(mean, std)을 입혀준다.
Style Randomization(SR) 적용
두 feature z, z'을 alpha 만큼 interpolate 한 새로운 mean, std를 사용한다(두 이미지의 style을 alpha만큼 섞음)
style을 섞는것과 다른 style로 바꾸는것은 다르다
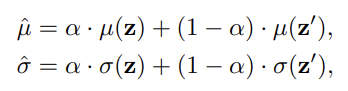
두 이미지의 Style Representation을 섞은것으로 AdaIN(z, z') 하여 z의 style을 바꾼다
- input x와 x'에서 추출된 feature의 모든 chnnel-wise mean과 std를 구하고, 두 feature의 style을 interpolate한 값으로 z feature를 바꿔준다(x 이미지의 style이 변경되는 효과) 그리고 style이 변경된 feature로 예측을 진행한다

Content Randomization(CR) 적용
랜덤하게 선택된 이미지 feature(z')의 style을 input 이미지 feature(z)의 style로 Adaptive Instacne Nomalization를 적용하여 랜덤 이미지의 content는 유지하되, style은 input 이미지로 변경한다. 이후 변경된 feature로 예측을 진행한다.
Network 개별 학습 구현
https://github.com/facebookresearch/DomainBed
def update(self, minibatches, unlabeled=None):
all_x = torch.cat([x for x, y in minibatches])
all_y = torch.cat([y for x, y in minibatches])
# learn content
self.optimizer_f.zero_grad()
self.optimizer_c.zero_grad()
loss_c = F.cross_entropy(self.forward_c(all_x), all_y)
loss_c.backward()
self.optimizer_f.step()
self.optimizer_c.step()
# learn style
self.optimizer_s.zero_grad()
loss_s = F.cross_entropy(self.forward_s(all_x), all_y)
loss_s.backward()
self.optimizer_s.step()
# learn adversary
self.optimizer_f.zero_grad()
loss_adv = -F.log_softmax(self.forward_s(all_x), dim=1).mean(1).mean()
loss_adv = loss_adv * self.weight_adv
loss_adv.backward()
self.optimizer_f.step()
return {'loss_c': loss_c.item(), 'loss_s': loss_s.item(),
'loss_adv': loss_adv.item()}참고
DBSA seminar
https://blog.lunit.io/2018/04/24/deep-supervised-domain-adaptation/
Deep Supervised Domain Adaptation
머신 러닝은 영상 처리나 자연어 처리등의 문제를 쉽게 해결하는 강력한 기법이지만, 학습에 충분한 데이터가 존재하는 문제에서만 성능을 낼 수 있다는 단점이 있습니다. 특히, 딥 러닝을 적용
blog.lunit.io
https://velog.io/@goe87088/%EB%85%BC%EB%AC%B8-Reducing-Domain-Gap-by-Reducing-Style-Bias-SagNets
[논문] Reducing Domain Gap by Reducing Style Bias (SagNets)
이번에 리뷰할 논문은 'Reducing Domain Gap by Reducing Style Bias (SagNets)'이다.
velog.io
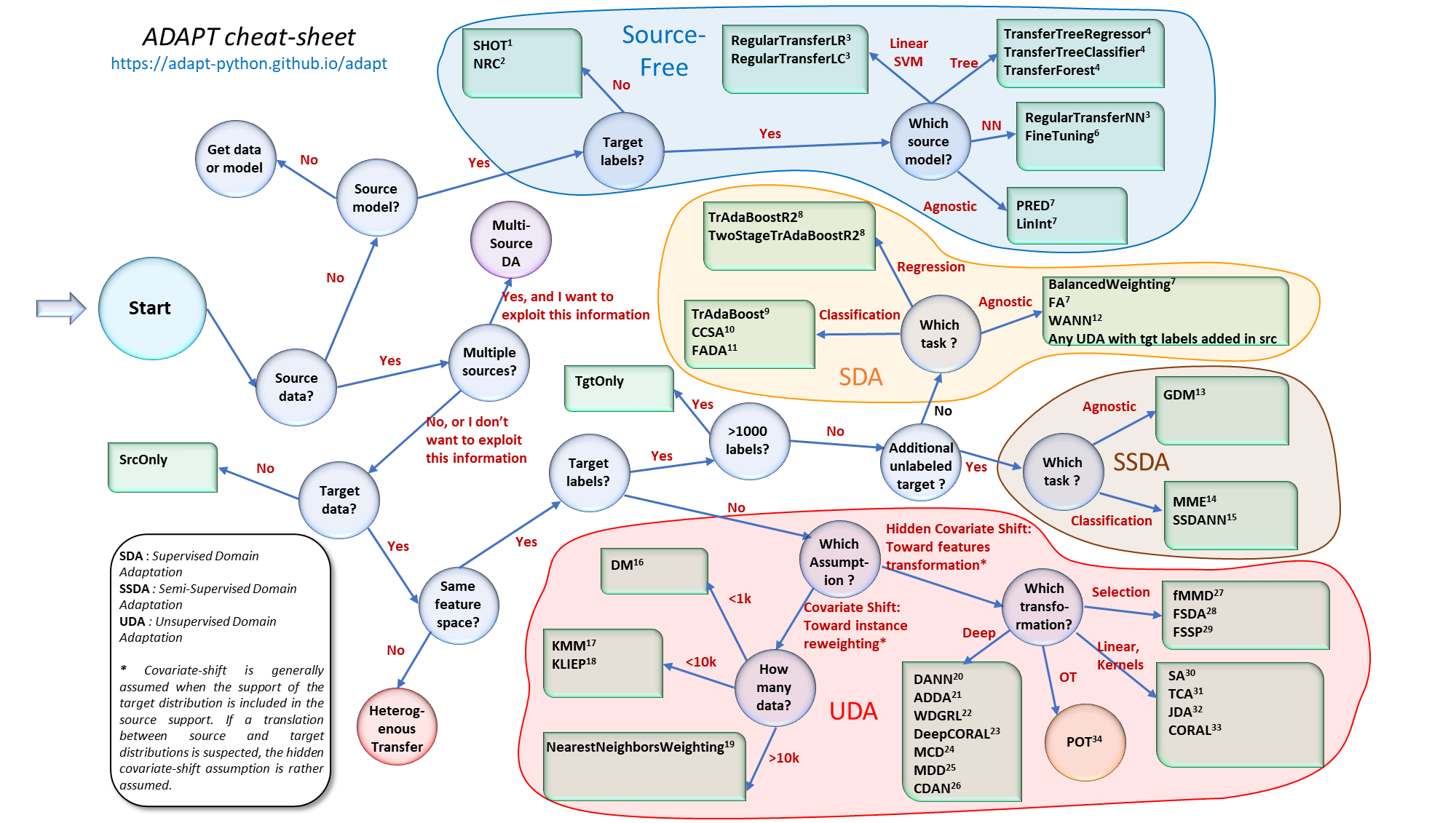
Adaption Domain 알고리즘 참고 사이트
https://adapt-python.github.io/adapt/map.html
Selecting the right domain adaptation model — adapt 0.1.0 documentation
Selecting the right domain adaptation model When facing a new domain adaptation problem, it can be particularly difficult to choose the appropriate transfer learning algorithm. The flowchart below has been designed to help the user to quickly identify whic
adapt-python.github.io
'대학원 입시 > Paper Review' 카테고리의 다른 글
| Normalization Techniques (0) | 2022.09.30 |
|---|